OLTP와 OLAP는 서로 다른 목적으로 사용되는 두 가지 유형의 데이터베이스 시스템입니다.
OLTP(Online Transaction Processing) 시스템은 데이터가 자주 업데이트되거나 추가되는 트랜잭션 처리를 위해 설계되었습니다. 이러한 시스템은 고객 주문 또는 은행 거래 처리와 같이 대량의 짧고 간단한 거래를 처리하는 데 최적화되어 있습니다. OLTP 시스템에서 데이터는 일반적으로 중복성을 최소화하고 업데이트를 최적화하기 위해 정규화된 방식으로 구성됩니다. OLTP 데이터베이스에 대한 인증은 일반적으로 사용자, 역할 및 권한 관리를 위한 메커니즘을 제공하는 데이터베이스 관리 시스템에 의해 처리됩니다.
OLAP(온라인 분석 처리) 시스템은 보고서 생성 또는 시간 경과에 따른 추세 분석과 같은 복잡한 쿼리에서 대량의 데이터를 분석하도록 설계되었습니다. 이러한 시스템은 집계 및 계산과 관련된 복잡한 쿼리를 처리하는 데 최적화되어 있으며 일반적으로 의사 결정 및 비즈니스 인텔리전스 목적으로 사용됩니다. OLAP 시스템에서 데이터는 일반적으로 쿼리 성능을 최적화하기 위해 비정규화된 방식으로 구성됩니다. OLAP 데이터베이스에 대한 인증도 일반적으로 데이터베이스 관리 시스템에서 처리합니다.
SAP HANA는 OLTP 및 OLAP 워크로드를 모두 지원합니다. 인증을 위해 SAP HANA는 사용자, 역할 및 권한을 관리하기 위한 다양한 메커니즘을 제공합니다. 여기에는 SAML, LDAP, Kerberos 및 X.509 인증서와 같은 인증 옵션이 포함됩니다. 또한 SAP HANA는 사용자가 사용 권한이 있는 데이터 및 기능에만 액세스할 수 있도록 RBAC(역할 기반 액세스 제어)를 제공합니다. SAP HANA는 또한 감사 로깅 및 모니터링 기능을 제공하여 보안 정책 및 규정 준수를 보장합니다.
OLTP and OLAP are two different types of database systems that are used for different purposes.
OLTP (Online Transaction Processing) systems are designed for transactional processing, where data is frequently updated or added. These systems are optimized for handling high volumes of short, simple transactions, such as processing customer orders or bank transactions. In an OLTP system, data is typically organized in a normalized way to minimize redundancy and optimize updates. Authentication for OLTP databases is typically handled by the database management system, which provides mechanisms for managing users, roles, and privileges.
OLAP (Online Analytical Processing) systems are designed for analyzing large volumes of data in complex queries, such as generating reports or analyzing trends over time. These systems are optimized for handling complex queries that involve aggregations and calculations, and are typically used for decision-making and business intelligence purposes. In an OLAP system, data is typically organized in a denormalized way to optimize query performance. Authentication for OLAP databases is also typically handled by the database management system.
When it comes to SAP HANA, it supports both OLTP and OLAP workloads. For authentication, SAP HANA provides a variety of mechanisms for managing users, roles, and privileges. These include authentication options such as SAML, LDAP, Kerberos, and X.509 certificates. In addition, SAP HANA provides role-based access control (RBAC) to ensure that users only have access to the data and functions that they are authorized to use. SAP HANA also provides audit logging and monitoring capabilities to ensure compliance with security policies and regulations.
Event: Normal NotTriggerScaleUp 9m14s cluster-autoscaler pod didn't trigger scale-up: 9 max node group size reached, 1 pod has unbound immediate PersistentVolumeClaims Normal NotTriggerScaleUp 4m12s (x27 over 9m4s) cluster-autoscaler pod didn't trigger scale-up: 1 pod has unbound immediate PersistentVolumeClaims, 9 max node group size reached Warning FailedScheduling 4s (x10 over 9m16s) default-scheduler 0/8 nodes are available: 8 pod has unbound immediate PersistentVolumeClaims.
말그대로 bound 되지 않은 PVC가 존재한다는 뜻이다.
Interpret this error(상세설명):
The first two log messages indicate that the cluster-autoscaler pod did not trigger a scale-up of the cluster because the maximum node group size has been reached and there are pods with unbound immediate PVCs. This means that there are no available nodes to schedule the new pods with unbound PVCs. The third log message indicates that the default scheduler failed to schedule the pods because all nodes have unbound immediate PVCs.
To do: investigate why the PVCs are not binding to any available storage resources. Check the status of your storage classes, persistent volumes, and persistent volume claims to ensure that they are configured correctly and have available capacity. You may also need to adjust the resource requests and limits for your pods to ensure they fit within the available resources. Once you have resolved the PVC binding issue, the cluster-autoscaler should be able to trigger a scale-up of the cluster to accommodate the new pods.
재생성을 위하여 PV가 삭제되는 중이었으나 계속 Terminating 상태로 삭제가 안되고 있었다.
모든 작업 완료 및 세션 만료 후 정리중이라 원래 확인과는 다를 수 있다. 아래는 terminating 상태의 예이다.
pod는 삭제했고 (replicas 0) 관련 pvc를 get해보니 이전 네임스페이스에 있던 pvc가 pending 상태였고 새로 생성한 네임스페이스에 생성된 삭제대상 pvc가 물려있는 상태였다.
한번 storage class를 설정하여 배포한 후 수정하려고 하면 바꿀수 없는(immutable) 항목이라 PersistentVoluemClain is invalid 에러가 발생하며 반영이 안된다. (Forbidden: spec is immutable after creation except resources.requests for bound claims)
compare standard with gp2:
In Kubernetes, standard and gp2 are storage classes that refer to different types of cloud storage volumes that can be attached to the cluster. standard is a default storage class that uses pd-standard persistent disks in Google Cloud or gp2 in AWS. These volumes provide balanced performance and cost, and they are suitable for general-purpose workloads. On the other hand, gp2 is an AWS-specific storage class that uses gp2 EBS volumes. These volumes are optimized for transactional workloads and offer higher performance than standard volumes. They also cost more per GB than standard volumes. Therefore, when choosing between standard and gp2, it depends on your workload requirements, budget, and the cloud provider you are using.
작업중 configmap not found와 함께 마운트 실패가 난다면
Warning FailedMount 62s (x13 over 11m) kubelet MountVolume.SetUp failed for volume "grafana-ini-cm" : configmap "grafana.ini" not found
생명은 성장하고 표현하며 스스로 살아가는 경향이 있다. 이 성향이 좌절되면 생명을 향하던 에너지가 붕괴 과정을 거쳐 파괴로 향하는 에너지로 변한다. 생명이 실현될수록 파괴성의 힘도 줄어든다. 파괴성은 살지 못한 삶의 결과다.
고통은 인생의 최악이 아니다. 최악은 무관심이다. 고통스러울 때는 그 원인을 없애려 노력할 수 있다. 하지만 아무 감정도 없을 때는 마비된다.
하지만 우리는 기계가 아니다! 삶은 목적을 위한 수단이 아니라 그 자체가 목적이다. 우리가 삶을 사랑한다면 삶의 과정이, 다시 말해 변하고 성장하며 발전하고, 더 자각하며 깨어나는 과정이 그 어떤 기계적 실행이나 성과보다 훨씬 더 중요하다.
사랑은 행동, 소유, 사용이 아니라 존재에 만족하는 능력이다.
삶을 사랑하기 힘든 또 다른 이유는 행동의 관료화가 심해지기 때문이다. 최대의 경제성을 목표로 개인을 재단해 적절한 집단 구성원 형식에 맞추.. (생략) 그러면 개인은 능력 있고 규율을 잘 지키지만 더 이상 그 자신이 아니며 온전히 생명력을 발휘하지 못하기에 삶을 사랑하는 그의 능력은 마비되고 만다.
All objects or subset of objects based on prefix or tags
All objects or subset of objects based on prefix or tags
Use cases
Disaster recovery, data locality, compliance with geographic data storage regulations
Data redundancy, compliance with data storage regulations, high availability
Benefits
Ensures availability of data even in case of regional outage, complies with geographic data storage regulations
Ensures availability of data in case of service disruption or bucket unavailability, complies with data storage regulations
AWS S3 복제를 사용하면 데이터 중복, 규정 준수 및 재해 복구와 같은 다양한 목적을 위해 동일하거나 다른 AWS 리전에 있는 버킷 간에 객체를 복제할 수 있습니다. AWS S3에서 사용할 수 있는 복제 유형에는 CRR(Cross-Region Replication)과 SRR(Same-Region Replication)의 두 가지 유형이 있습니다.
CRR(Cross-Region Replication)은 서로 다른 AWS 리전의 버킷 간에 객체를 복제하는 데 사용됩니다. CRR은 버킷의 모든 객체 또는 접두사 또는 태그를 기반으로 객체의 하위 집합을 복제할 수 있습니다. CRR은 여러 대상 버킷에 대한 복제를 지원하며 재해 복구 및 데이터 지역성에 사용할 수 있습니다.
동일 리전 복제(SRR)는 동일한 AWS 리전의 버킷 간에 객체를 복제하는 데 사용됩니다. SRR은 버킷의 모든 객체 또는 접두사 또는 태그를 기반으로 객체의 하위 집합을 복제할 수 있습니다. SRR은 데이터 중복, 규정 준수 및 고가용성을 위해 사용할 수 있습니다.
CRR과 SRR의 주요 차이점은 복제 대상입니다. CRR은 서로 다른 AWS 지역의 버킷에 객체를 복제하고 SRR은 동일한 AWS 지역의 버킷에 객체를 복제합니다. 이 차이는 각 복제 유형의 사용 사례에 영향을 미칩니다.
CRR은 재해 복구 및 데이터 지역성이 필요한 조직에 적합합니다. 개체를 다른 지역의 버킷에 복제함으로써 조직은 지역 중단이 발생한 경우에도 데이터를 사용할 수 있도록 보장할 수 있습니다. CRR은 데이터를 특정 지역에 저장해야 한다는 규정 요구 사항을 준수하는 데에도 사용할 수 있습니다.
반면 SRR은 데이터 중복성과 규정 준수가 필요한 조직에 적합합니다. 개체를 동일한 지역의 버킷에 복제함으로써 조직은 서비스 중단이 있거나 버킷을 사용할 수 없게 되더라도 데이터를 사용할 수 있도록 보장할 수 있습니다. SRR은 또한 데이터를 여러 위치에 저장해야 한다는 규정 요구 사항을 준수하는 데 사용할 수 있습니다.
요약하면 CRR과 SRR은 모두 AWS S3에서 데이터 관리를 위한 중요한 도구입니다. CRR은 재해 복구 및 데이터 지역성에 사용되는 반면 SRR은 데이터 중복 및 규정 준수에 사용됩니다. CRR과 SRR 사이의 선택은 조직의 특정 요구 사항과 요구 사항에 따라 다릅니다.
AWS S3 replication allows you to replicate objects between buckets in the same or different AWS regions for various purposes, such as data redundancy, compliance, and disaster recovery. There are two types of replication available in AWS S3: Cross-Region Replication (CRR) and Same-Region Replication (SRR).
CrossRegion Replication (CRR) is used to replicate objects between buckets in different AWS regions. CRR can replicate all objects in a bucket or just a subset of objects based on prefix or tags. CRR supports replication to multiple destination buckets and can be used for disaster recovery and data locality.
SameRegion Replication (SRR) is used to replicate objects between buckets in the same AWS region. SRR can replicate all objects in a bucket or just a subset of objects based on prefix or tags. SRR can be used for data redundancy, compliance, and high availability.
The main difference between CRR and SRR is the destination of replication. CRR replicates objects to buckets in different AWS regions, while SRR replicates objects to buckets in the same AWS region. This difference affects the use cases of each replication type.
CRR is suitable for organizations that require disaster recovery and data locality. By replicating objects to buckets in different regions, organizations can ensure that their data is available even in the event of a regional outage. CRR can also be used to comply with regulatory requirements that mandate data must be stored in specific geographic regions.
SRR, on the other hand, is suitable for organizations that require data redundancy and compliance. By replicating objects to buckets in the same region, organizations can ensure that their data is available even if there is a service disruption or if a bucket becomes unavailable. SRR can also be used to comply with regulatory requirements that mandate data must be stored in multiple locations.
In summary, CRR and SRR are both important tools for data management in AWS S3. CRR is used for disaster recovery and data locality, while SRR is used for data redundancy and compliance. The choice between CRR and SRR depends on the organization's specific needs and requirements.
Designed for frequently accessed data with low latency and high throughput.
S3 Intelligent-Tiering
Optimizes costs by automatically moving data to the most cost-effective access tier based on changing access patterns.
S3 Standard-Infrequent Access (S3 Standard-IA)
Designed for data that is accessed less frequently but requires rapid access when needed.
S3 One Zone-Infrequent Access (S3 One Zone-IA)
Designed for data that is accessed less frequently and can be recreated if lost.
S3 Glacier
Designed for data archiving and long-term backup that requires infrequent access.
Amazon S3 Glacier Instant Retrieval: delivers the lowest-cost storage for long-lived data that is rarely accessed and requires retrieval in milliseconds
Amazon S3 Glacier Flexible Retrieval: low-cost storage, up to 10% lower cost (than S3 Glacier Instant Retrieval), for archive data that is accessed 1—2 times per year and is retrieved asynchronously.
S3 Glacier Deep Archive
Designed for long-term data archiving that is accessed once or twice a year. In other words, S3’s lowest-cost storage class and supports long-term retention and digital preservation for data that may be accessed once or twice in a year. for the customer such as financial services, healthcare, and public sectors
S3 Outpost
use the S3 API to store and retrieve data in the same way that they access and consume data in regular AWS Regions. This means that many tools, apps, scripts, or utilities that already use the S3 API, either directly or through the SDK, can be configured to store that data locally on Outposts.
ideal for workloads with local data residency requirements, and to satisfy demanding performance needs by keeping data close to on-premises applications.
한글 버전:
객체 클래스
설명
S3 Standard
저지연 및 고 처리량으로 자주 액세스되는 데이터에 적합합니다.
S3 Intelligent-Tiering
액세스 패턴이 변경됨에 따라 가장 비용 효율적인 액세스 계층으로 자동으로 데이터를 이동하여 비용을 최적화합니다.
S3 Standard-Infrequent Access (S3 Standard-IA)
자주 액세스되지 않지만 필요할 때 빠른 액세스가 필요한 데이터에 적합합니다.
S3 One Zone-Infrequent Access (S3 One Zone-IA)
자주 액세스되지 않지만 손실됐을 때 재생성이 가능한 데이터에 적합합니다.
S3 Glacier
적은 빈도로 액세스하는 데이터 아카이빙 및 장기 백업에 적합합니다.
Amazon S3 Glacier Instant Retrieval
거의 액세스하지 않지만 밀리초 내에 검색이 필요한 장기 데이터에 대해 최저 비용 저장소를 제공합니다.
Amazon S3 Glacier Flexible Retrieval
약 1년에 1~2회 액세스되는 아카이브 데이터를 비동기적으로 검색하기 위한 저비용 저장소로, S3 Glacier Instant Retrieval보다 최대 10% 더 낮은 비용을 제공합니다.
S3 Glacier Deep Archive
약 1년에 1~2회 액세스되는 장기 데이터 아카이빙에 적합합니다. S3의 가장 저렴한 저장소 클래스로, 장기 보존 및 디지털 보존을 지원합니다. 금융 서비스, 의료, 공공 분야와 같은 고객을 대상으로 합니다.
S3 Outpost
일반적인 AWS 지역에서 데이터를 액세스하고 사용하는 방법과 동일하게 S3 API를 사용하여 데이터를 저장하고 검색할 수 있습니다. 이는 이미 S3 API를 직접 또는 SDK를 통해 사용하는 많은 도구, 앱, 스크립트 또는 유틸리티를 Outposts에서도 구성하여 데이터를 로컬로 저장할 수 있게 해줍니다. 이는 로컬 데이터 레지던시 요구사항을 충족시키는 작업 부하 및 온프레미스 애플리케이션에 대한 빠른 성능 요구사항을 만족시키는 데 이상적입니다.
Amazon S3 Glacier Flexible Retrieval과 AWS S3 Glacier Deep Archive의 주요 차이점은 사용 사례와 검색 시간입니다.
Amazon S3 Glacier Flexible Retrieval은 일반적으로 연간 1~2회 비동기식으로 자주 액세스하지 않는 데이터를 보관하는 데 적합한 저비용 스토리지 옵션입니다. S3 Glacier Instant Retrieval에 비해 최대 10% 저렴한 비용을 제공하지만 검색 시간은 몇 분에서 몇 시간까지 길어질 수 있습니다. 이 스토리지 클래스는 장기간 보존을 위해 많은 양의 데이터를 저장해야 하고 더 긴 검색 시간을 허용할 수 있는 조직에 이상적입니다.
반면 AWS S3 Glacier Deep Archive는 1년에 한두 번만 액세스하는 장기 데이터 아카이빙을 위해 설계되었습니다. 모든 S3 스토리지 클래스 중에서 가장 비용이 저렴한 스토리지 클래스이지만 검색 시간이 가장 길어 최대 12시간이 소요될 수 있습니다. 이 스토리지 클래스는 규정 준수 및 규정상의 이유로 데이터를 보존해야 하고 데이터에 즉시 액세스할 필요가 없는 금융 서비스, 의료 및 공공 부문과 같은 고객에게 적합합니다.
요약하면 S3 Glacier Flexible Retrieval은 가끔 비동기식으로 액세스할 수 있는 데이터를 보관하는 데 적합하고 S3 Glacier Deep Archive는 거의 액세스하지 않고 가장 긴 검색 시간을 견딜 수 있는 데이터를 보관하는 데 적합합니다.
적응형 비트전송률 스트리밍 (ABR) 은 HTTP로 스트리밍하는 것을 향상시키는 방법이다.
동영상을 인코딩하고 길이가 몇 초 인 더 작은 파일로 분할하여 세그먼트로 전송되도록 하고 (분할 프로세스)
엔드 유저의 연결이 버퍼링없이 스트리밍할정도로 빠르게 해당 영상을 다운로드 할 수 없으면 유저의 비디오 플레이어가 세그먼트 완료 후 더 작은 파일로 전환한다. (조정 프로세스)
처음 시작시에는 비디오 플레이어가 가능한 작은 비트 전송률 파일을 요청해서 시작하고 더 높은 비트 전송률 파일이 처리 가능해지면 클라이언트가 처리가능한 선에서 가장 높은 비트전송률 파일을 선택하고, 이상적으로 선정되면 해당 비트 전송률로 계속 세그먼트를 요청한다.
해당 방법으로 비디오 재생 품질이 향상될 수 있는 이점이 있다. (비디오 품질 수준 다이나믹하게 변경)
ABR을 지원하는 프로토콜은 HLS, DASH, HDS 가 있다.
HLS (HTTP Live Streaming):HLS는 주문형 및라이브 스트리밍 용으로 작동하며H.264또는 H.265 인코딩 형식이필요하다 .일부 프로토콜과 달리 HLS는 특수 서버를 사용할 필요가 없다.원래 HLS는 Apple 장치와만 호환되었지만 이제는 장치에 구애받지 않고있다.그러나 Apple 장치는 HLS 형식만 허용한다.
DASH (Dynamic Adaptive Streaming over HTTP):DASH는 특정 인코딩 표준을 요구하지 않는다.(HLS는 특정 인코딩 형식이 필요한 반면 DASH는 대부분의 인코딩 표준 사용 다 가능. MPEG-DASH는 국제 표준)또한 모든원본 서버는HTTP를통해 실행되기 때문에 DASH 스트림을 제공하도록 설정할 수 있다.(항상 서버의 방화벽에서 오픈하는 80, 443 같은 포트 이용되서 차단 위험이 낮아짐)HLS 이외의 다른 모든 형식과 마찬가지로 DASH 형식은 Apple 장치에서 작동하지 않는다. 즉 HLS는 애플 장치에서 지원해서 이용가능하지만 MPEG-DASH는 아니어서 해당 방식으로 전송되는 비디오를 애플제품은 재생할 수 없다.
HDS (HTTP Dynamic Streaming):원래 Adobe Flash(단종됨)와 함께 작동하도록 설계된 이 형식은 주문형 또는 라이브 스트리밍에 사용할 수 있으며 HTTP 연결을 통해 작동한다. HDS 형식은 비디오를 MP4에서 F4F(조각화된 MP4)로 변환해야하며 H.264 인코딩 표준.Apple 장치는 HDS 프로토콜과 호환되지 않는 유일한 장치다.
HLS와 DASH는 모두 HTTP를 통해 실행되고 전송 프로토콜로 TCP를 쓰고 세그먼트로 비디오를 구분하며 ABR을 제공하는 유사점이 있으나 위 특징으로인해 차이점이 존재한다.
AWS Cloudfront는 현재 HLS와 MPEG-DASH를 지원하고 있다.
HLS를 통해 사용자의 bandwidth에 따라 다이나믹하게 비디오 품질을 향상시킬 수 있고
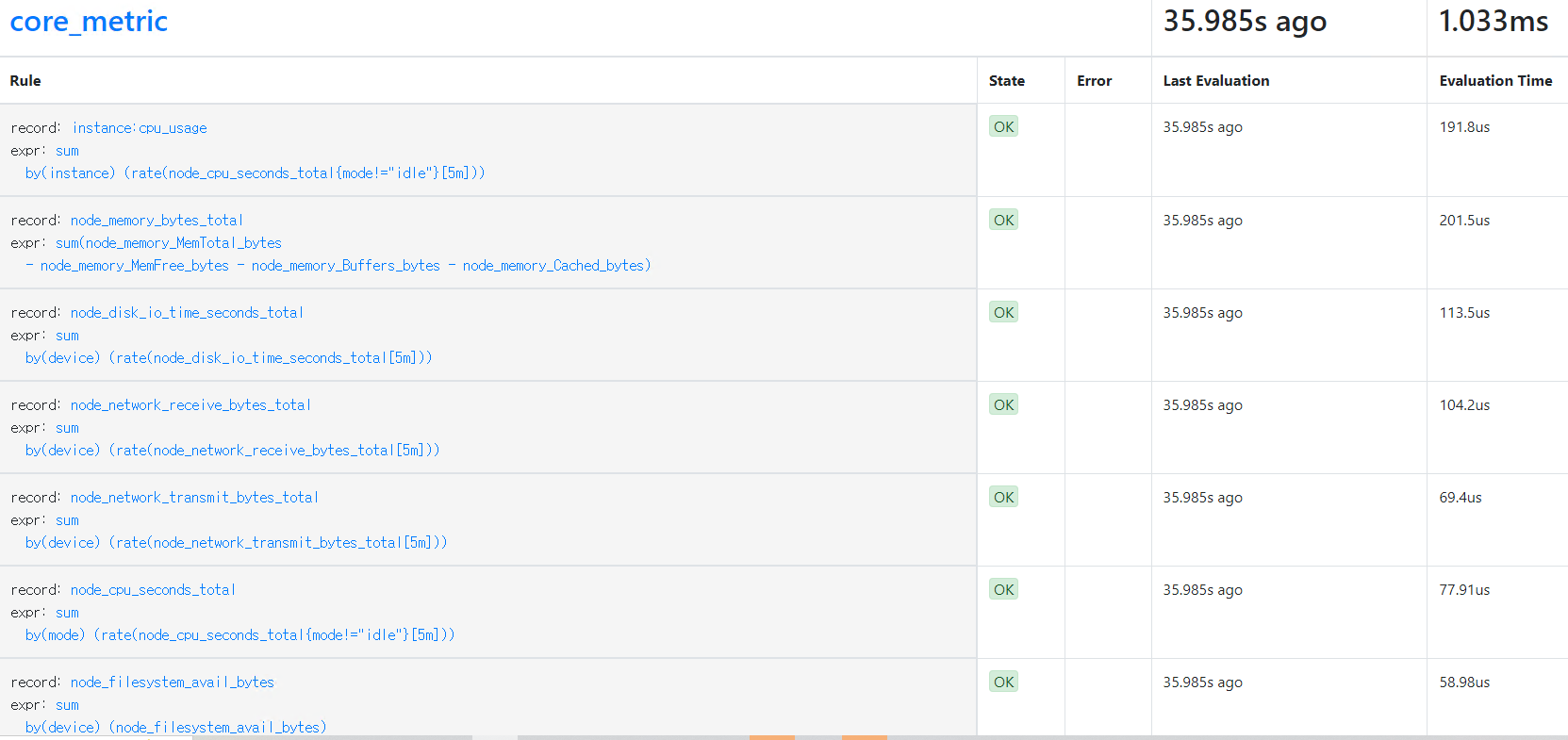
설치한 prometheus 메인 config yaml 파일에 recording_rules.yml, alertiing_rules.yml 항목이 data 필드로 존재하는 것을 확인했으며 해당 부분에 주요 major라고 생각하는 메트릭을 추가해보았다.
추가한 recording_rules 는 다음 항목과 같았다.
recording_rules.yml: |
groups:
- name: core_metric
rules:
- record: instance:cpu_usage
expr: sum(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (instance)
- record: node_memory_bytes_total
expr: sum(node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes)
- record: node_disk_io_time_seconds_total
expr: sum(rate(node_disk_io_time_seconds_total[5m])) by (device)
- record: node_network_receive_bytes_total
expr: sum(rate(node_network_receive_bytes_total[5m])) by (device)
- record: node_network_transmit_bytes_total
expr: sum(rate(node_network_transmit_bytes_total[5m])) by (device)
- record: node_cpu_seconds_total
expr: sum(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (mode)
- record: node_filesystem_avail_bytes
expr: sum(node_filesystem_avail_bytes) by (device)
- record: node_filesystem_size_bytes
expr: sum(node_filesystem_size_bytes) by (device)
- record: node_filesystem_free_bytes
expr: sum(node_filesystem_free_bytes) by (device)
- record: node_filesystem_used_bytes
expr: sum(node_filesystem_size_bytes - node_filesystem_free_bytes) by (device)
다음은 알럿과 연관된 alert 룰이다.
data:
alerting_rules.yml: |
groups:
- name: core_alerts
rules:
- alert: HighCpuUsage
expr: sum(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (instance) > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "High CPU usage detected"
description: "CPU usage is above 90% for at least 5 minutes."
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes) / node_memory_MemTotal_bytes > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "High memory usage detected"
description: "Memory usage is above 90% for at least 5 minutes."
각각 정의한 네임인 core_metric과 core_alerts 가 다음과 같이 배포되어 프로메테우스 페이지에서 확인되었다.
배포는 메인 컨피그 yaml 파일을 kubectl apply -f config.yaml 식으로 배포하였고, 배포하면 running 중인 pod에 반영이 되는데 테스트하다가 pod를 재생성하려고 delete를 하였다. pod 삭제 후 기본 설정에 따라 pod 하나와 container 두개가 새로 생성되었지만 해당 nlb 타겟그룹에서 unhealthy로 기록되었다.
아래는 grafana 배포관련 캡처이지만 비슷한 상태였던것 같다.
pod description을 보니 아이피가 바뀐 것을 확인하고 해당 파드의 보안그룹을 허용해주고, 그 파드 안에서 프로세스를 확인해보니 9090 포트로 계속 TIME_WAIT 가 나고 connection refused가 나는 것을 확인했다.
메인 컨피그 yaml에서 다음 항목을 줄여주고, 해당 배포 pod ec2에서 sysctl 설정을 업데이트 하였다.
저장 후 나와서 sudo sysctl -p 커맨드 입력 (위 ipv4.tcp_tw_reuse 값 설정은 timeout wait 상태의 소켓 수를 줄이고 포트를 더 빨리 풀어줌. tw_recycle은 리눅스 커널 버전 4.12 이후 deprecated) netstat 으로 9090 포트 확인9090 포트의 target 서버 ip로 요청 및 정상적으로 응답오는 것을 확인 (location 헤더에 /graph 라고 보임) 후,해당 Prometheus 의 AWS NLB 타겟 그룹에 기존에 명시적으로 들어가있던 아이피 대신 타겟 아이피 register, healthy로 바뀌는 것을 확인하였다.아직 상태는 미흡하지만 프로메테우스로 어디까지 커스텀 가능한지 지속해서 확인해봐야겠다.
alerting_rules.yml
recording_rules.yml
kubectl로 prometheus 확인 시 유용했던 명령어 정리:
kubectl logs -f prometheus-pod-name -n namespaceofpm -c prometheus-containername | more (해당 pod에 컨테이너 여러개일때 특정 컨테이너 지정하여 로그 확인 방법)
kubectl get pods <prometheus-pod-name> -n <namespace> -o jsonpath="{.spec.containers[*].name}" (해당 pod의 컨테이너를 찾을때)
kubectl describe configmap fluentd-config
kubectl get configmap -n <namespace> -l app=fluentd -o yaml (app이 fluentd인 configmap yaml파일 찾기)
kubectl kill -s HUP <prometheus-pod-name> -n <namespace> (안먹을때도 있음 버전따라)
kubectl rollout restart deployment/<grafana-deployment-name> -n <namespace> (apply 후 pod 삭제 없이 deploy)
kubectl get deployments -n <namespace> (deployment 이름 찾기)